会议论文概况
今年的SIGCOMM会议从225篇中论文中录用了39篇,录取率为17.3%。会议一共5天时间,从周一持续到周五,中间三天是论文主进程,周一和周五是各类workshop和教学。为期三天的主进程以获得SIGCOMM终身成就奖的Jim Kurose教授的演讲开场。据说全世界的网络学子们都读过他的书,正是写《计算机网络–自顶向下方法》的这位教授,阐述了他对计算机网络的教育、科研、教学和服务的一些观点。
登录主会现场的总共有41篇论文,包括39篇同行评议论文和2篇CCR最佳论文。其中39篇论文划分为11个技术session,分散在周二到周四的6个半天中举行。2篇CCR论文放在周四下午的收尾部分。21个poster、18个demo、13篇主会论文的poster/demo和6篇工业界的demo交错安排在茶歇时间,这让会议的总体节奏显得很紧凑。
此外,微软亚洲研究院的李博杰同学也有一篇博客对会议上的技术方向进行了分析,可以让读者对今年大会的状况有一个比较详细的认识。我这里会侧重分享自己对大会论文阅读的一些笔记。
首先来看看今年主会上的论文分布,11个技术session包括:
- SDN & NFV I、SDN & NFV II;共4+3=7篇
- Datacenters I、Datacenters II;共4+3=7篇
- Wide Area Networks;共3篇
- Monitoring and Diagnostics;共3篇
- Scheduling;共4篇
- Verification;共4篇
- Networked Applications;共3篇
- Wireless;共5篇
- Censorship and Choice;共3篇
可以看到数据中心网络,SDN和NFV依然是最火热的部分,总共有14 篇相关论文。而5篇wireless session的论文或成最大赢家,因为他们狂揽了会议上总共3篇最佳论文中的2篇。
接下我将主要对SDN和数据中心相关的14篇论文进行概括的介绍。SDN&NFV的内容安排在三天主会程的第一个session和最后一个session。第一天上午有四篇论文。
SDN-NFV I
1. ClickNP: Highly Flexible and High Performance Network Processing
来自微软亚洲研究院,谭琨老师的作品。关于这篇论文的背景,可以直接引用论文作者李博杰的话:
通用处理器的摩尔定律遇到了瓶颈,数据中心的计算规模、用户需求的灵活性却与日俱增。微软数据中心的解决方案是可编程硬件,即FPGA。微软开发了一套Catapult Shell作为FPGA的操作系统,加速必应搜索、网络、存储等,并把研究成果通过多篇论文共享给学术社区。微软Catapult团队也与Altera合作开发了适用于Catapult Shell的OpenCL BSP,以便使用Altera OpenCL框架编程FPGA,这是ClickNP项目的基础。
正如连线杂志的一篇文章微软将未来押注于FPGA芯片所分析,微软非常看好FPGA技术在未来服务器和网络设备中的应用,Catapult项目就是其中的重要部分。所以在高速网络处理体系结构的进化方向上,FPGA也是微软重要技术方向。谭琨老师设计的ClickNP,致力于解决传统FPGA编程调试困难的问题,打造更加友好的高速网络数据包处理的FPGA编程环境,最终希望软件程序员通过高级语言就可以写出高性能的网络处理程序。
2. Packet Transactions: High-Level Programming for Line-Rate Switches
这是来自MIT的Anirudh Sivaraman、Nick McKeown等的作品,项目由Barefoot Networks开发实现。
同样是使用高级语言实现数据平面线速的可编程性:实现支持有状态的数据平面算法AQM等。论文详细说明了如何将高级语言编译成可以在emerging programmable line-rate switching chips运行的低级代码。
作者设计了一个C-like语言来表达data-plane算法。为了支持线速可编程的有状态算法,论文介绍了一系列关于数据包处理的原子。与微软押注FPGA不同的是,Nick更看好可编程交换机芯片。
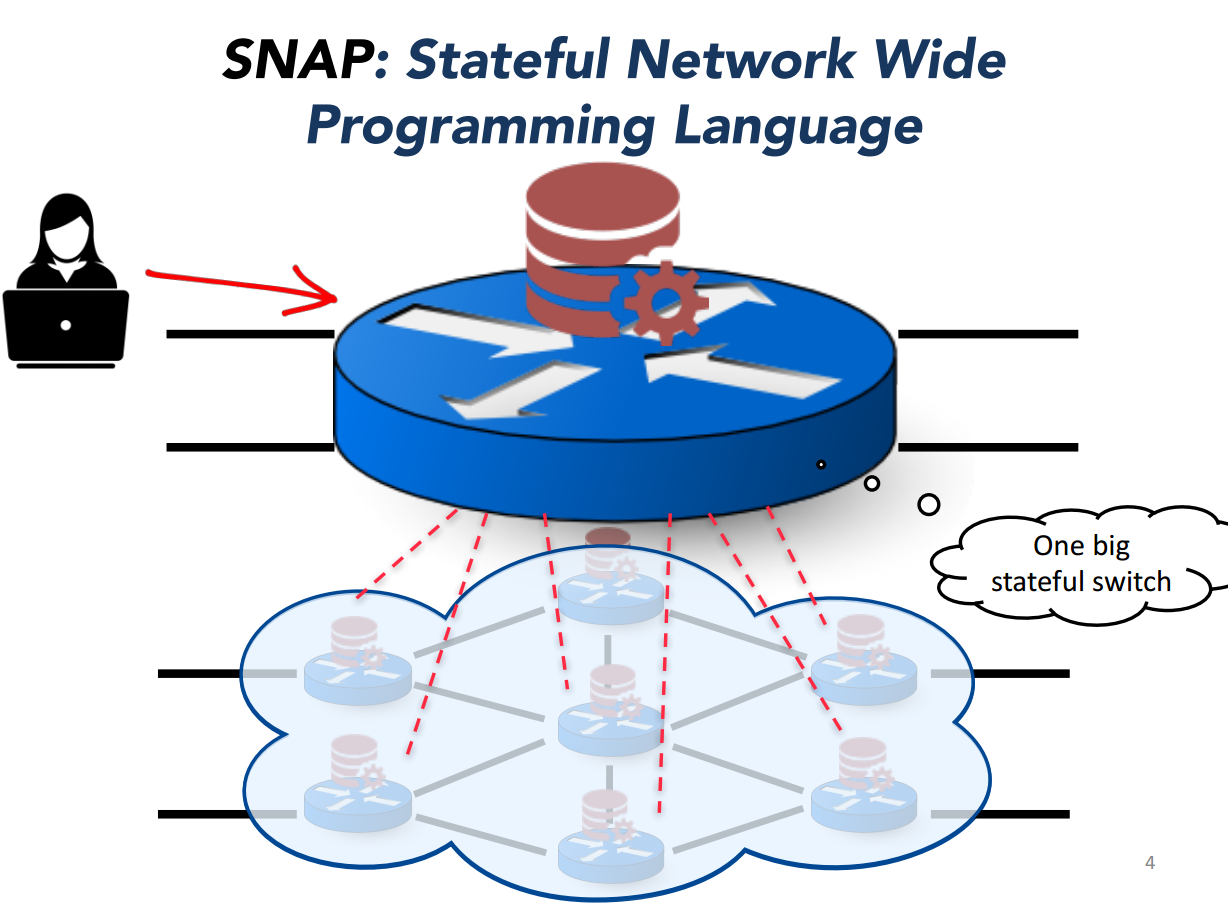
3. SNAP: Stateful Network-Wide Abstractions for Packet Processing
来自普林斯顿大学Jennifer团队的作品。
随着SDN的发展,新兴的软硬件交换机支持了越来越多的(不依赖与控制器的)持续状态。正确有效的管理这个有状态的、分布式系统是一个非常有挑战性的编程问题。为了简化这个问题,论文提出了SNAP,如下图所示。SNAP给用户提供的是一个中心化的编程模型,用户只需要在一个big switch上进行编程,包括读写全局的变量,实现防火墙或者流量测量等应用。
4. Programmable Packet Scheduling at Line Rate
这同样是MIT的Anirudh Sivaraman以及Nick McKeown等的作品,由Barefoot Networks开发。
论文提出一种在不需要改变交换机硬件的情况下实现可编程的数据包调度算法。数据包调度的终极问题就是如何、何时调度数据包。作者观察到在大多数的调度算法中,这两个决定都是在进入队列的是时候做出的。基于此观察,论文提出一个统一的抽象PIFO(push-in first-out queue)–优先级队列来决定调度顺序和时间。论文还设计了支持这个调度器的硬件设计,用于64口10G的交换机。

SDN-NFV II
5. Dataplane Specialization for High-performance OpenFlow Software Switching
作者单位是TrafficLab, Ericsson Research;位于布达佩斯,匈牙利。
(1)Abstract
OpenFlow是具有强大表现力的数据平面编程语言, 但是这种强大的表现力需要损失性能为代价:因为交换机必须要在快通道做过多的包分类。这得Openflow软件交换机架构必须建立在flow caching的基础上,但是这this imposes intricate limitations on the workloads that can be supported efficiently,也会导致malicious cache overflow attacks。
这篇文章认为,Openflow不应该对所有的应用使用全局统一的flow cache semantics,也不应对通用情况(common case)进行优化,相反地,a switch should rather automatically specialize its dataplane piecemeal with respect to the configured workload.
论文提出了ESwitch交换机架构,使用on-the-fly基于模板的代码生成方式,将openflow pipeline编译到机器码,并可以作为fast path. 作者说“Our prototype can easily scale beyond 100 Gbps on a single Intel blade even with complex OpenFlow pipelines.”
(2)Story
伴随虚拟化的浪潮,越来越多的openflow应用运行在x86平台之上。 然而用一句话来讲,Openflow性能遇到了瓶颈。“OpenFlow is expressive but troublesome to make fast on x86”.
Flow caching在基于丰富匹配域转发的应用场景中表现很差[19,29]:传输层防火墙,产生短周期流量应用produce short-lived flows, e.g., peer-to-peer protocols, Map Reduce, or network monitoring。
作者认为,这一切问题都在于flow caching太通用化了。例如OVS, uses a hash based wildcard match store as (one of the hierarchy levels of) its flow cache, which works fairly well for simple OpenFlow pipelines but inherently breaks down for large-scale IP routing (that would rather require LPM) or flow tables that heavily match across layer boundaries。
We argue, an OpenFlow switch should rather automagically specialize itself for the actual workload, into an optimal exact matching switch when the flow tables specify pure L2 MAC forwarding, an LPM engine for L3 routing, or a fast, optimized packet classifier for L4 ACLs, and a reasonable combination of these building blocks whenever the OpenFlow pipeline matches heterogeneous protocol header fields.
论文把openflow看做是一种用于对数据面编程的declarative language。而ESwitch就是将declarative pipeline specification转换为机器码的编译器。
作者在DPDK实现该系统。可以轻松达到100Gbps的传输速度,在features predictable and superior performance, latency and multi-core scalability领先OVS最多达到两个数量级,完全超越同时代的硬件openflow交换机。
6. PISCES: A Programmable, Protocol-Independent Software Switch
作者是Nick Feamster, Nick McKeown, Jennifer Rexford这三位来自普林斯顿、斯坦福大学的三位大神和他们的弟子。
当前网络中,管理程序通过软件交换机来控制出入VMs的数据包。这些软件交换机又经常需要升级或者定制化:为了支持新的协议报头、encapsulations for tunneling and overlays,来提高网络测量和debugging特性、甚至增加middlebox功能。
软件交换机通常是基于大量的代码:包括内核代码。而改变这些代码是一件极其艰难的事情,因为这需要a formidable undertaking requiring domain mastery of network protocol design and developing, testing, and maintaining a large, complex codebase.
作者认为改变软件交换机对数据包的转发行为不应该要求关于软件交换机实现的细节。相反,应该通过一种高级domain-specific language(DSL)语言的方式,如P4,来指定如何处理和转发数据包,这种语言可以直接被编译到软件交换机中执行。
论文提出了PISCES,一个从OVS进化来的软件交换机,其行为有P4来定制。PISCES是协议无关的,这种独立性使得他能很容易的添加新的功能。论文中详细说明了编译器如何分析high-level的规则得到优化的转发性能。比起OVS,PISCES需要改变的代码比OVS少40倍。
7. OpenBox: A Software-Defined Framework for Developing, Deploying, and Managing Network Functions
一个软件定义的网络功能开发、部署和管理的框架。作者是Anat Bremler-Barr、Yotam Harchol、David Hay,来自以色列赫兹利亚Herzliya的School of Computer Science, The Interdisciplinary Center,以及以色列耶路撒冷的The Hebrew University希伯来大学。
作者将SDN分离数据平面和控制平面的思想应用在了网络功能虚拟化上。论文的故事是说:在当前的网络中,各种网络功能可能运行在不同的硬件设备上,比如防火墙,DPI等,但是这些功能中大都包含相同的操作,这些冗余的操作给数据包带来了很大的传输时延。
Datacenter I
1. Globally Synchronized Time via Datacenter Networks
这是来自Cornell大学的Ki Suh Lee, Han Wang等的作品。
数据中心中的时钟同步至关重要。但是目前的时钟同步协议如NTP、PTP从设计根源上就受到网络中数据包交换特征的影响。特别的,网络抖动、交换机中的包缓存、流调度都会给数据包的往返时间带来不确定性因素,然而精确的时钟同步必须要求正确的测量才能实现。
论文提出了DTP(数据中心时钟同步协议),DTP不用数据包进行同步,精度却能够达到纳秒级别。本质上,DTP使用网络设备的物理层来实现时钟同步协议。正因为DTP不会给2层数据包增加任何负载,所以DTP几乎不会增加网络的overhead。但是DTP必须要求部署专门的网络设备才能实现。作者说明了DTP中,直接相连节点之间的时钟同步精度在25.6ns以内,6个节点以内的数据中心时钟同步精度在153.6ns以内。理论上限是4TD,其中T是最快的时钟(约6.4ns),D是两个服务器之间的最长跳数。在软件中,DTP守护进程能够在4T(约25.6ns)精度以内获取DTP的时钟,由此计算,网络中端到端的时钟同步精度在4TD+8T纳秒以内。
2. Robotron: Top-down Network Management at Facebook Scale
来自Facebook的Yu-Wei Eric Sung等的作品。
主要介绍了Facebook的网络运维项目Robotron:一种自顶向下的大型生产网络管理系统。Robotron的目标是通过将人与网络设备的直接交互最小化来降低网络管理的工作量和出错率。网络工程师只需要向Robotron表达高级的网络管理意图,Robotron系统就可以将其翻译为低级的设备配置并且安全自动的部署到设备上。Robotron也可以监控网络设备的状态并确认网络的真实状态不会与设计状态相违背。Facebook从2008年起就已经开始使用Robotron来管理位于全球的数万台网络设备以及相连的数十万服务器。

3. RDMA over Commodity Ethernet at Scale
微软郭传雄等的作品。
这篇论文介绍了一种应用于大型数据中心网络内部通过二层以太网实现的RDMA(远程直接内存访问)技术RoCEv2,全称RDMA over commodity Ethernet。RoCEv2技术设计主要用来支持微软的高可靠性、延迟敏感的应用。
为了摆脱VLAN的限制,作者设计了一种基于DSCP的优先流控(priority flow-control)机制PFC,实现了在大型数据中心网络的部署。作者解决了PFC带来的死锁问题、RDMA传输的活锁、NIC PFC暂停帧风暴等挑战性问题。
作者说明了RoCEv2在大规模网络中的安全性问题和可扩展性问题是可以解决的,并且说明了RDMA可以代替数据中心网络内部的TCP实现低延迟、低CPU负载、高吞吐的通信。
有趣的是,作者认为传统的TCP/IP协议栈已经无法满足新一代数据中心网络的需求了,主要有两个原因。第一是因为TCP/IP协议栈对CPU的消耗太大。当前软硬件上实现的优化技术checksum offloading, large segment offload (LSO), receive side scaling (RSS) and interrupt moderation都没有帮助。第二是因为数据中心有很多应用对时延极度敏感,比如搜索,但是TCP无法提供低时延。不仅内核对数据包的处理时延可能达到数十毫秒,而且由于网络拥塞导致的丢包也无法彻底杜绝。

4. ProjecToR: Agile Reconfigurable Data Center Interconnect
这是MSR的Monia Ghobadi、Ratul Mahajan等的作品。脑洞很大。
论文提出一种基于光学的数据中心互连系统。作者使用DMD(光开关的一种,利用旋转反射镜实现光开关的开合,开闭为微秒量级)和镜面组合作为发射器,顶部的光电探测器作为接收器。这种装置可以实现任意两个rack之间实现直接互连,并且两个rack之间的重连可以在12微秒内完成。为了将数据包从源rack发送到目的rack,系统的发射器和接收器之间的可以灵活的通过数百万中方式实现动态互连。利用这种灵活性,作者还开发了相应的网络拓扑和路由算法。作者利用真实数据中心网络流量实验后声称,这种基于光学的方法可以比商业的folded-Clos interconnect平均提高流的完成时间达30-95%,成本下降达到25-40%。
Datacenter II
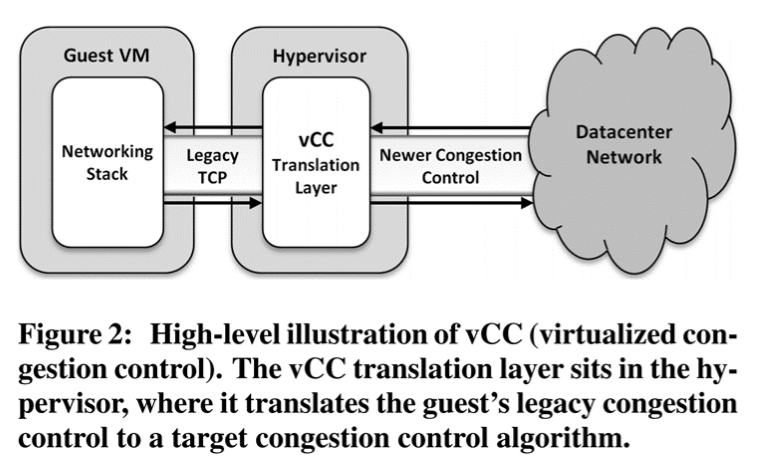
5. Virtualized Congestion Control
这是来自Vmware公司和斯坦福合作的作品,又有Nick.M的参与。
这是关于数据中心中拥塞控制算法的论文。背景是各种新兴的拥塞控制算法不断的提出以及应用于多租户的数据中心,改善了网络的质量:延迟减小,吞吐量增大,公平性更高。但是传统的应用无法更新到行的操作系统版本,导致其无法应用新的拥塞控制算法,这会影响全网的性能。
论文提出的VCC可以对不同的拥塞控制协议进行翻译,使得传统的应用也可以从新的控制算法中获益。论文在linux kernel 以及VMware的管理程序ESXI中实现了系统。
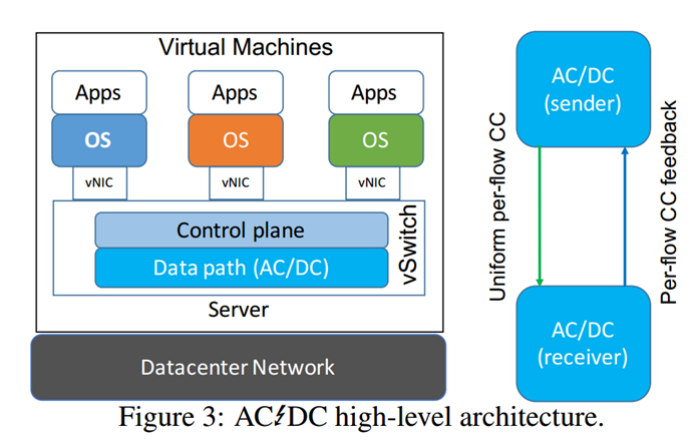
6. AC/DC TCP: Virtual Congestion Control Enforcement for Datacenter Networks
来自威斯康辛麦迪逊大学和IBM合作的作品。一作是中国人Keqiang He。同样是解决多租户数据中心拥塞控制的问题,作者的思想是使用一个统一的管理程序来控制VMs中TCP拥塞控制算法,并且不改变VMs以及网络硬件。AC/DC TCP在虚拟交换中强制per-flow拥塞控制方法来控制任意租户的TCP协议栈。
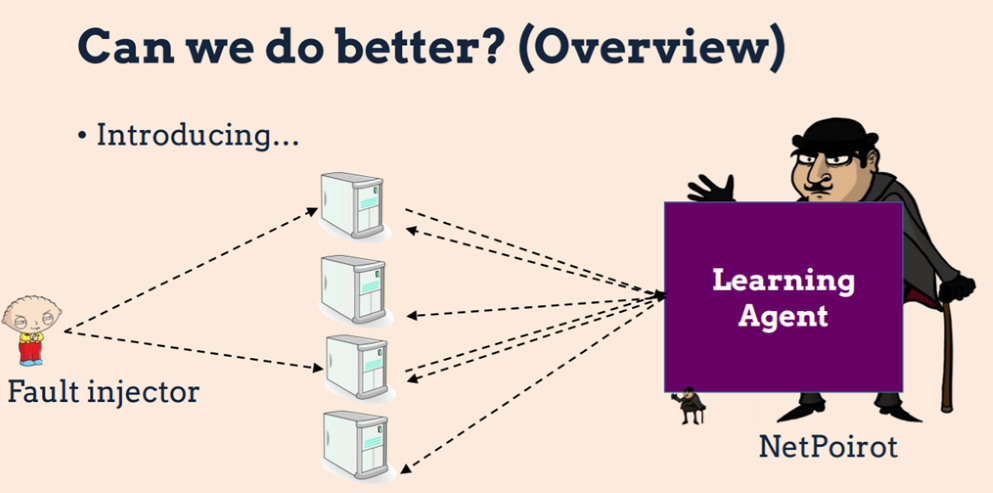
7. NetPoirot: Taking The Blame Game Out of Data Center Operations
这是宾西法利亚州大学和微软合作的作品。
论文是讲如何使用TCP测量数据中心网络故障诊断的。数据中心网络出现故障时,是客户的问题还是网络的问题?论文提出的网络侦探实际上是一个基于机器学习的分类算法:首先通过一个客户端收集TCP的统计信息(这是持续不断地30s一次,轻量级),网络侦探通过对这些数据的分析将错误划分到某种类型的问题上去。有点像我们Windows系统中的网络故障诊断。
Censorship and Choice
三篇论文,其中一篇是二层协议的重新设计。
1. An Internet-Wide Analysis of Traffic Policing
南加州和谷歌合作的作品。使用了大量的数据集270 billion packets served to 28,400 client ASes,分析发现有7%左右的连接是are identified to be policed(流量监督管制)。这些连接的丢包率是普通连接的6倍多。
2. The Deforestation of L2
UC berkery的作品。他们重新思考了二层协议:二层协议最大的特点就是基于STP的flood-and-learn。而STP最大的问题就是生成树的同事丢弃了很多有效的链接,而丢弃有效的链接就意味着丢弃了网络中有效容量,导致网络拓扑改变时网络的恢复速度就很慢。一个改进就是二层设备三层化,引入控制层。但是本文提出用于企业网和小型数据中心的二层机制。关键是
- Extend Ethernet
- Treeless flooding,Duplicate-packet-detection
- Extend Header:记录hop、sw id、flood flag、learnable flag
- Separate queues:交换机有flood队列和普通队列
3. Neutral Net Neutrality
斯坦福NICK的作品。中立的网络中立性。网络的中立性是指网络中是否应该有网络应用被特别对待?本文从用户的角度来处理网络的中立性。作者发现:用户确实想要某些应用得到区别对待,并且用户的这些偏好呈现长尾分布的特征,所以one-size-fits-all的方法是不适用的。
由此作者设计了network cookies,一种让用户表达自己偏好的通用机制。
学术小结
通过对SIGCOMM2016会议上有关Datacenter和SDN/NFV论文的了解,可以发现当前的数据中心网络以及SDN的研究热点和发展方向。
数据中心的研究热点包括大规模网络的运维(Facebook的Robotron,微软的NetPoirot),高性能网络(微软的高可靠性低延迟项目RDMA),时钟同步等(Cornell的时钟同步)和数据中心网络内部的拥塞控制(VCC和AC/DC)。
SDN/NFV的研究热点包括高可编程、高性能的数据平面(包括微软MSRA的ClickNP,斯坦福的可编程的线速交换机,队列调度模型,普林斯顿的SNAP),高性能的软件交换机(爱立信的ESwitch,普林斯顿哈佛等的PISCES),软件定义中间件(OpenBox)。
从SDN/NFV相关的几篇论文中,我们也可以发现各方对于SDN数据平面技术演化方向的看法,主要有三类:第一是通用的可编程交换芯片,就像PC领域的CPU,用户只需通过高级语言就可以对线速交换芯片进行编程。这算是对SDN最美好的畅想了,代表人物就是Nick McKeown。第二类进化方向则是以FPGA为主,结合通用CPU实现高速数据包的转发,以微软为代表。第三类则是以x86服务器为载体,通过高性能的软件交换机实现高性能的网络处理,而这正是不少企业当前阶段正在实际应用的技术,以OVS为代表。